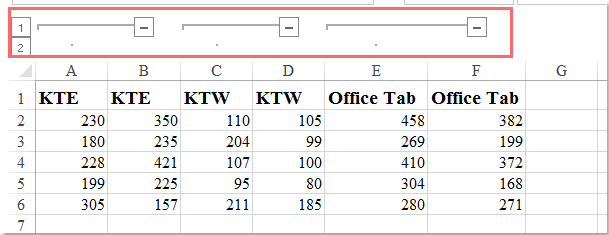
We can group the resultset in SQL on multiple column values. All the column values defined as grouping criteria should match with other records column values to group them to a single record. Let us use the aggregate functions in the group by clause with multiple columns.

This means given for the expert named Payal, two different records will be retrieved as there are two different values for session count in the table educba_learning that are 750 and 950. Grouping on multiple columns is most often used for generating queries for reports, dashboarding, etc. Group by is done for clubbing together the records that have the same values for the criteria that are defined for grouping. When a single column is considered for grouping then the records containing the same value for that column on which criteria are defined are grouped into a single record for the resultset. There's an additional way to run aggregation over a table. If a query contains table columns only inside aggregate functions, the GROUP BY clause can be omitted, and aggregation by an empty set of keys is assumed.
And finally, we will also see how to do group and aggregate on multiple columns. A query expression that corresponds, in the form of its select list, to a second query expression that follows the UNION, INTERSECT, or EXCEPT operator. The two expressions must contain the same number of output columns with compatible data types; otherwise, the two result sets can't be compared and merged.

Set operations don't allow implicit conversion between different categories of data types; for more information, see Type compatibility and conversion. Once the rows are divided into groups, the aggregate functions are applied in order to return just one value per group. It is better to identify each summary row by including the GROUP BY clause in the query resulst. All columns other than those listed in the GROUP BY clause must have an aggregate function applied to them.

The SQL GROUP BY Statement The GROUP BY statement groups rows that have the same values into summary rows, like "find the number of customers in each country". The GROUP BY statement is often used with aggregate functions to group the result-set by one or more columns. The column names returned in the result of a set operation query are the column names from the tables in the first query expression. Let's start be reminding ourselves how the GROUP BY clause works.

An aggregate function takes multiple rows of data returned by a query and aggregates them into a single result row. Spark also supports advanced aggregations to do multiple aggregations for the same input record set via GROUPING SETS, CUBE, ROLLUP clauses. The grouping expressions and advanced aggregations can be mixed in the GROUP BY clause and nested in a GROUPING SETS clause. See more details in the Mixed/Nested Grouping Analytics section. When a FILTER clause is attached to an aggregate function, only the matching rows are passed to that function.

All the expressions in the SELECT, HAVING, and ORDER BY clauses must be calculated based on key expressions or on aggregate functions over non-key expressions . In other words, each column selected from the table must be used either in a key expression or inside an aggregate function, but not both. This syntax allows users to perform analysis that requires aggregation on multiple sets of columns in a single query. Complex grouping operations do not support grouping on expressions composed of input columns.

Including the GROUP BY clause limits the window of data processed by the aggregate function. This way we get an aggregated value for each distinct combination of values present in the columns listed in the GROUP BY clause. The number of rows we expect can be calculated by multiplying the number of distinct values of each column listed in the GROUP BY clause. In this case, if the rows were loaded randomly we would expect the number of distinct values for the first three columns in the table to be 2, 5 and 10 respectively.
So using the fact_1_id column in the GROUP BY clause should give us 2 rows. The reason is that SQL has to choose a value for that field from the many rows in the group, and it is possible that the field you added could have more than one value within that group. This isn't a concern with the columns in the GROUP BY because the way the groups are created ensures that every row has the same value in the column that we're grouping by. It also isn't a concern with aggregate functions like SUM because they "collapse" the column to a single value. In SQL, the GROUP BY statement is used to group the result coming from a SELECT clause, based on one or more columns in the resultant table. GROUP BY is often used with aggregate functions to group the resulting set by one or more columns.
If the WITH TOTALS modifier is specified, another row will be calculated. This row will have key columns containing default values , and columns of aggregate functions with the values calculated across all the rows (the "total" values). So GROUP BY allows us to split up a table into groups that share a value in a particular column, and then apply aggregate functions to get a single value by "collapsing" the group. The aggregate functions work exactly the same as they do on a whole table, but operate only on the rows in each group. Use theSQL GROUP BYClause is to consolidate like values into a single row. The group by returns a single row from one or more within the query having the same column values.

Its main purpose is this work alongside functions, such as SUM or COUNT, and provide a means to summarize values. First, you specify a column name or an expression on which to sort the result set of the query. If you specify multiple columns, the result set is sorted by the first column and then that sorted result set is sorted by the second column, and so on. The GROUP BY clause divides the rows returned from the SELECTstatement into groups. For each group, you can apply an aggregate function e.g.,SUM() to calculate the sum of items or COUNT()to get the number of items in the groups.

FILTER is a modifier used on an aggregate function to limit the values used in an aggregation. All the columns in the select statement that aren't aggregated should be specified in a GROUP BY clause in the query. For set operations, two rows are treated as identical if, for each corresponding pair of columns, the two data values are either equal or both NULL.
Can you group by two columns in SQL For example, if tables T1 and T2 both contain one column and one row, and that row is NULL in both tables, an INTERSECT operation over those tables returns that row. The UNION, INTERSECT, and EXCEPT set operators are used to compare and merge the results of two separate query expressions. If you want to know which website users are buyers but not sellers, you can use the EXCEPT operator to find the difference between the two lists of users. If you want to build a list of all users, regardless of role, you can use the UNION operator. WITH CUBE modifier is used to calculate subtotals for every combination of the key expressions in the GROUP BY list.

WITH ROLLUP modifier is used to calculate subtotals for the key expressions, based on their order in the GROUP BY list. Grouping with a Case Statement Build a CASE STATEMENT to GROUP a column with an alias or new string. Using GROUP BY allows you to divide rows returned from the SELECT statement into groups. In this lesson you learned to use the SQL GROUP BY and aggregate functions to increase the power expressivity of the SQL SELECT statement. You know about the collapse issue, and understand you cannot reference individual records once the GROUP BY clause is used.

The HAVING clause is used instead of WHERE with aggregate functions. While the GROUP BY Clause groups rows that have the same values into summary rows. The having clause is used with the where clause in order to find rows with certain conditions. The having clause is always used after the group By clause. The aggregation can be performed more effectively, if a table is sorted by some key, and GROUP BY expression contains at least prefix of sorting key or injective functions. In this case when a new key is read from table, the in-between result of aggregation can be finalized and sent to client.

This behaviour is switched on by the optimize_aggregation_in_order setting. Such optimization reduces memory usage during aggregation, but in some cases may slow down the query execution. The Group By statement is used to group together any rows of a column with the same value stored in them, based on a function specified in the statement.

Generally, these functions are one of the aggregate functions such as MAX() and SUM(). This statement is used with the SELECT command in SQL. SQL allows the user to store more than 30 types of data in as many columns as required, so sometimes, it becomes difficult to find similar data in these columns. Group By in SQL helps us club together identical rows present in the columns of a table.

This is an essential statement in SQL as it provides us with a neat dataset by letting us summarize important data like sales, cost, and salary. The GROUP BY statement is often used with aggregate functions (COUNT(),MAX(),MIN(), SUM(),AVG()) to group the result-set by one or more columns. We can observe that for the expert named Payal two records are fetched with session count as 1500 and 950 respectively. Similar work applies to other experts and records too. Note that the aggregate functions are used mostly for numeric valued columns when group by clause is used. Criteriacolumn1 , criteriacolumn2,…,criteriacolumnj – These are the columns that will be considered as the criteria to create the groups in the MYSQL query.

There can be single or multiple column names on which the criteria need to be applied. We can even mention expressions as the grouping criteria. SQL does not allow using the alias as the grouping criteria in the GROUP BY clause. Note that multiple criteria of grouping should be mentioned in a comma-separated format. GROUP BY enables you to use aggregate functions on groups of data returned from a query.
In this power bi tutorial, we learned power bi sum group by multiple columns. And also we discussed the below points power bi sum group by two columns using power query. In this syntax, "column_name1" represents one or more columns returned by your query. It can be a field in table named by the FROM statement, a table alias from the SELECT list, or a numeric expression indicating the position of the column, starting with 1 to the left. SQL GROUP BY is the proper choice when you're selecting multiple columns from one or more tables, and also performing a mathematical operation while selecting them. You must GROUP BY all other columns except for the one with a mathematical operator.

And you can't group by columns with Memo, General, or Blob field properties. In the subtotals rows the values of already "grouped" key expressions are set to 0 or empty line. HAVING clause's key advantage is its ability to filter GROUPS using aggregate functions.
This is something you cannot do withing a SELECT statement. This is because the where statement is evaluated before any aggregations take place. The alternate having is placed after the group by and allows you to filter the returned data by an aggregated column. SQL Server allows you to sort the result set based on the ordinal positions of columns that appear in the select list. It is possible to sort the result set by a column that does not appear on the select list.

For example, the following statement sorts the customer by the state even though the state column does not appear on the select list. When you use the SELECT statement to query data from a table, the order of rows in the result set is not guaranteed. It means that SQL Server can return a result set with an unspecified order of rows. You can query data from multiple tables using the INNER JOIN clause, then use the GROUP BY clause to group rows into a set of summary rows.
We can use HAVING clause to place conditions to decide which group will be the part of final result-set. Also we can not use the aggregate functions like SUM(), COUNT() etc. with WHERE clause. So we have to use HAVING clause if we want to use any of these functions in the conditions. In this tutorial, you have learned you how to use the PostgreSQL GROUP BY clause to divide rows into groups and apply an aggregate function to each group.

They are excluded from aggregate functions automatically in groupby. Aggregate_function – These are the aggregate functions defined on the columns of target_table that needs to be retrieved from the SELECT query. Though it's not required by SQL, it is advisable to include all non-aggregated columns from your SELECT clause in your GROUP BY clause. Set operation that returns rows that derive from one of two query expressions. To qualify for the result, rows must exist in the first result table but not the second.

On the other hand, just as was the case with a SingleColumn, when multiple columns are passed to GROUP BY, it returns a single row. In the subtotals rows the values of all "grouped" key expressions are set to 0 or empty line. When a query has a GROUP BY, rather than returning every row that meets the filter condition, values are first grouped together.

The rows returned are the unique combinations within the columns. Similarly, we can run group by and aggregate on tow or more columns for other aggregate functions, please refer below source code for example. Similar to SQL GROUP BY clause, PySpark groupBy() function is used to collect the identical data into groups on DataFrame and perform aggregate functions on the grouped data.

In this article, I will explain several groupBy() examples using PySpark . I have a problem with group by, I want to select multiple columns but group by only one column. The query below is what I tried, but it gave me an error. I need a way to roll-up multiple rows into one row and one column value as a means of concatenation in my SQL Server T-SQL code. I know I can roll-up multiple rows into one row usingPivot, but I need all of the data concatenated into a single column in a single row.

In this tip we look at a simple approach to accomplish this. In this tutorial, you have learned how to use the SQL Server ORDER BY clause to sort a result set by columns in ascending or descending order. For each group, you can apply an aggregate function such as MIN, MAX, SUM, COUNT, or AVG to provide more information about each group. As we can see, the count function on "Dept_ID" returns the total number of records in the table, and the sum function on "Salary" returns the arithmetic sum of all the employees' salaries.
The columns to be retrieved are specified in the SELECT statement and separated by commas. Any of the aggregate functions can be used on one or more than one of the columns being retrieved. This is an important point a SQL developer must understand to avoid a common error when using the GROUP BY clause. After the database creates the groups of records, all the records are collapsed into groups. You can no longer refer to any individual record column in the query. In the SELECT list, you can only refer to columns that appear in the GROUP BY clause.





No comments:
Post a Comment
Note: Only a member of this blog may post a comment.